PowerInfer: 가정용 GPU로 서빙하는 LLM
PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU(Link)
TL;DR
CPU, GPU에 모델을 단순히 안 올리고 잘 올리면 훨씬 빠르다. 어떤 배경으로?
- 잘 나눠 올린다
- 대략 20%는 대부분의 입력에 대해서 항상 non-zero임: Hot activated
- 나머지(대략 80%) 입력에 따라 달라짐: Cold activated
- Hot은 GPU에 올려서 계산하고, Cold는 CPU에 올려서 계산한다
- 심지어 이 중 일부만 activate됨: 각각에 Predictor가 붙어서 activate될 Neuron만 골라서 계산함
- 잘 나눠 계산한다
- 기존의 다른 방법들은 CPU -> GPU로 올려서 계산함
- 근데 생각보다 걍 CPU에서 돌리는게 CPU -> GPU 올리고 GPU에서 계산하는것 보다 빠름(통신 비용)
- 그냥 CPU/GPU에서 각각 계산하고 GPU에서 취합해서 넘어감
- 즉 CPU-GPU data transfer를 줄임
- +a로 sparse operator도 잘 만들었음
그래서 얼마나 빨라짐?
- 4090에서의 token generation rate이 13.2 t/s로 A100보다 18%정도 느린 수치
- llama.cpp보다
11.69x3~4x 빠름- 결과 및 ablation을 참고해야함
- 11.69x는 llama.cpp 중 잘 구현되지 않은 모델과 비교한 내용이라고 함
큰 그림
문제 제기
- VRAM이 부족하므로 단순히 전체 LLM 모델을 가정용 GPU에 올려서 돌리는건 불가능함
- 예컨데 OPT-66B 모델을 4bit precision으로 quantize해도 40GB의 VRAM이 필요함
- llama.cpp 같은 라이브러리 들은 레이어를 CPU와 GPU에 나눠 올림으로써 이를 가능하게 했음
- 하지만, 논문에서는 CPU와 GPU의 통신 비용과 속도차이 등으로 단순히 모델을 나눠 올리는 것은 속도가 느릴 수 있음을 이야기함
- 요 부분을 어떻게 개선할 것인가가 주요한 토픽 중 하나
Prerequisite(+Related Work)
- LLM이 inference를 하는데 있어서, activation map의 10% 이하만이 non-zero value
- 그리고 심지어 이 activation이 어디일지 꽤 높은 정확도(93%)로 runtime에 이를 예측할 수 있음(Dejavu)
- non zero(sparse activation)를 보여주는 설명(Fig2.)
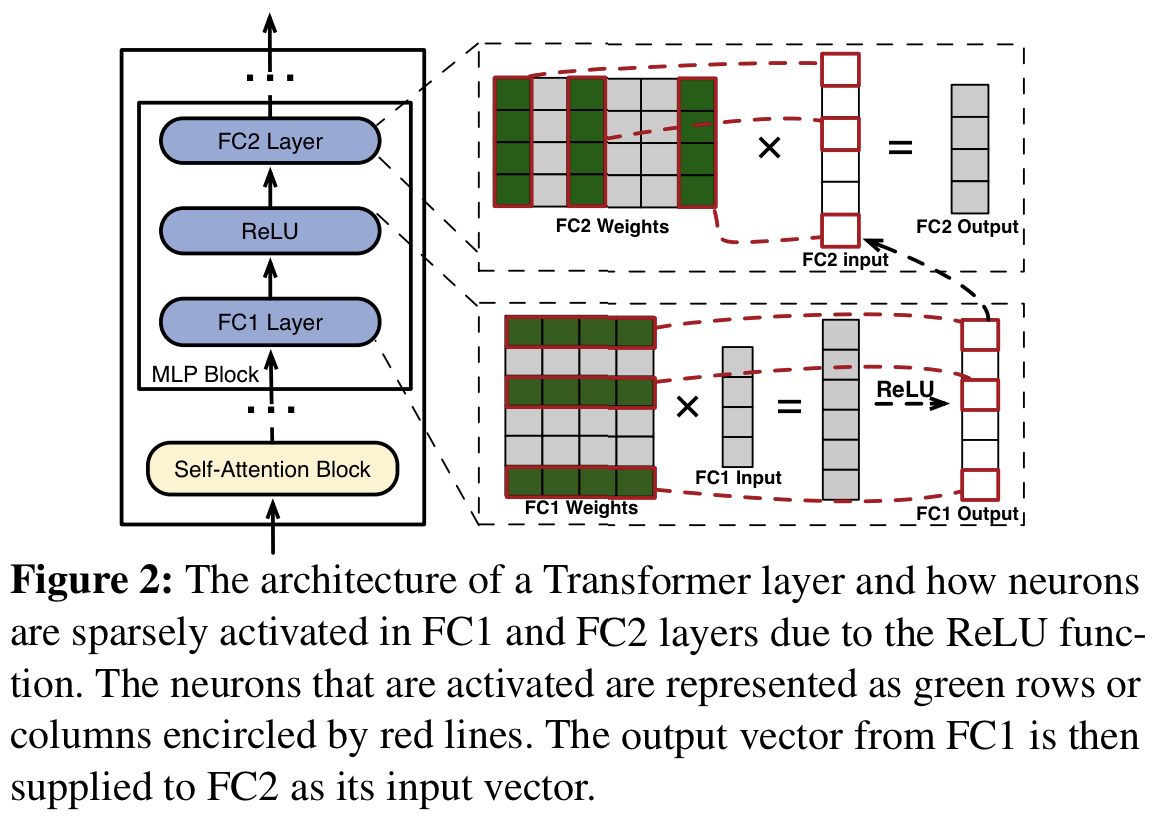
- weights 중 초록 부분이 active Neuron
- 입력과 곱해진 뒤 relu를 타면, 빨간 박스들만 non-zero
주요 insight
- 이 논문에서는 두가지 발견을 바탕으로 속도를 빠르게 개선할 방법을 고안했음
발견 1. 입력에 관계없이 항상 출력을 non zero로 만드는 Neuron이 존재함(마치 80-20 rule로): Power-law activation
- 위에서 activation output의 일부 만이 non-zero value를 갖는다고 했음
- 헌데 이 non-zero activation의 위치는 매 입력마다 다름
- (중요) 이 논문에서 여기서의 경향성을 찾아냄
- 전체 중 일부의 뉴런(weight matrix의 row 또는 column)은 다양한 입력에 대해서 거의 대부분 활성화됨(=output이 non-zero임)
- 나머지는 입력에 따라서 다른 부분이 활성화됨
80-20으로 끼워맞춰보면; 전체 중 20% 뉴런은 80%의 입력들(task들)에 대해서 activate됨(나머지는 때에 따라 다름)
- 이제 Neuron을 아래처럼 구분함
- 이 소수의 안바뀌는 코어한 친구들: Hot-activated
- 입력에 따라 바뀌는 대다수의 친구들: Cold-activated
- Fig5. 이미지는 특정 그룹의 뉴런들이 꾸준히 활성화되는 high degree of locality를 보여주는 이미지
- x축(Neuron 비율)에 따른 y축 누적분포가 일종의 활성화 비율을 보여줌
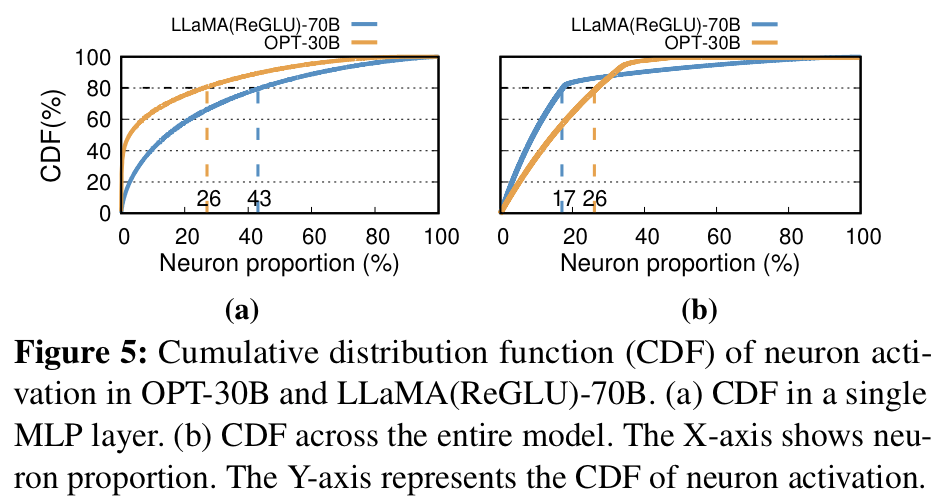
잘 안바뀌는 Hot-activated는 GPU에 올리고, 입력마다 바뀌는 Cold-activated는 CPU에 올려서 연산한다
발견 2. CPU computaion은 빠르다
- 기존의 방법론은 CPU에서 GPU로 올려서 계산함(Load-And-Execute)
- 발견 1을 고려하여, 일정 비율의 weight만 가져와서 CPU에서 직접 계산하면(Direct-Execute) 일정 batch size 이내에서는 속도가 더 빠름
- (참고) MLP 부분의 10%, Attention부분의 60%만 계산함
- 논문에서는 개별적인 inference에서는 이정도의 sparsity만으로 충분한 성능이 나온다고 함
디테일
PowerInfer architecture and workflow
- 전체 Overview(Fig7.)
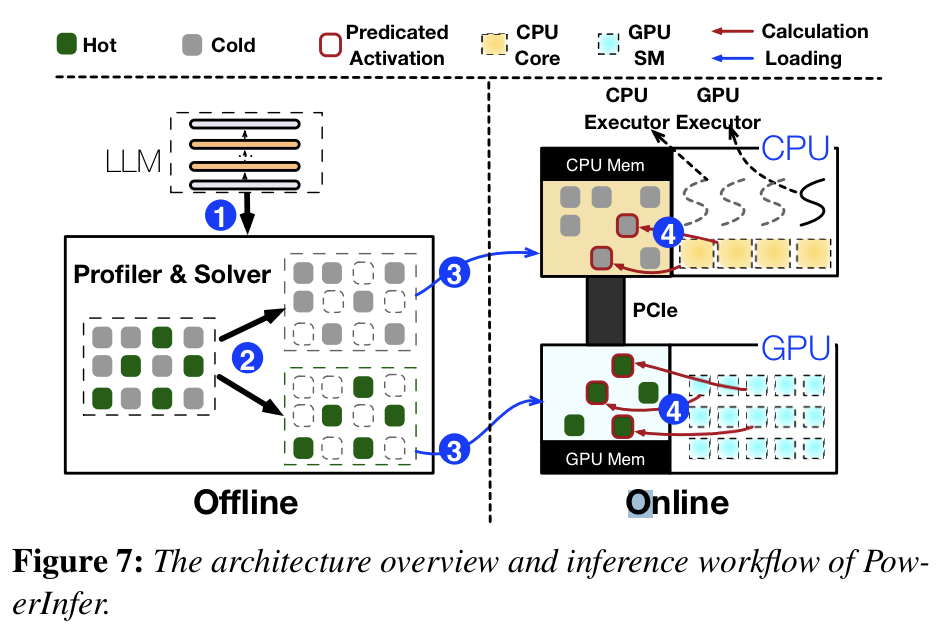
- LLM 내의 weight(Neuron)에 대해 미리 Hot, Cold를 나눠놓음(Offline)
- CPU, GPU memory 각각에서 Predictor로 Neuron activation을 예측하고, activate으로 예측될 Neuron만 memory에 올려서 계산함(Online)
레이어 하나 계산하는데 GPU, CPU가 나눠져서 일함 + Predictor로 더 효율적으로 일함
LLM Profiler and Policy Solver(Offline)
- general dataset을 통해서 Neuron이 Hot인지 Cold인지 구분함(fig 7. 파란 1)
- 이때 Neuron Impact Metric이라는 지표와 HW 스펙을 고려해서 workload를 배분함(fig 7. 파란 2)
- Integer Linear Programming으로 GPU의 impact metric을 maximize하도록 목적함수를 잡고 최적화로 workload를 배분함
Neuron-aware LLM Inference Engine(Online)
- 각 연산유닛(CPU/GPU)으로 두 타입의 Neuron을 각각 올림(Offline 결과를, fig 7. 파란 3)
- Runtime 시점에, CPU, GPU executor를 만들고, CPU-GPU를 각각 concurrent하게 연산함
- 이때 어떤 애들이 activate 될 지 Predictor를 통해서 선택한 뒤 연산함(fig 7. 파란 4)
- GPU에서 양쪽 결과를 합침
Single Layer Example
- 위 설명을 각 레이어에서 어떻게 수행하는지 보여주는 이미지(fig 8.)
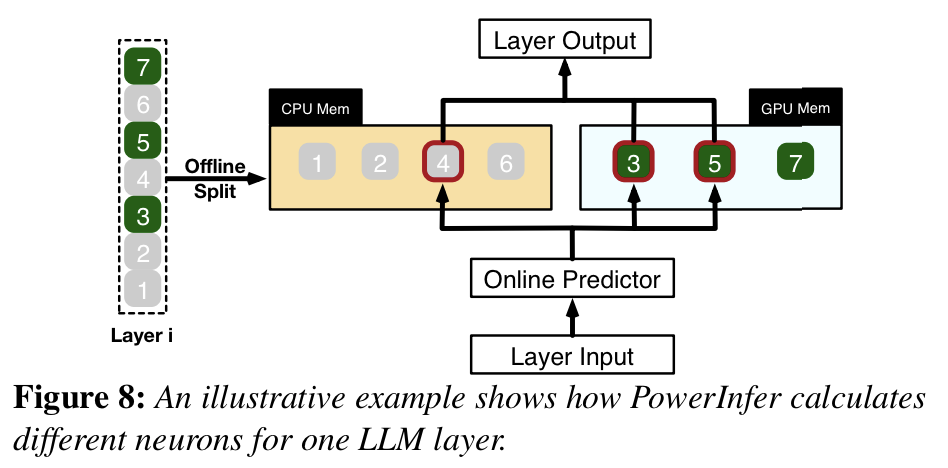
- Layer i는 Offline으로 이미 GPU, CPU 위에 나눠져서 올라가 있음
- weight의 1, 2, 4, 6번째는 CPU에
- 3, 5, 7은 GPU에
- Layer i로 들어오는 입력을 받으면, Online Predictor는 어떤 weight(Neuron)이 활성화되는지 “예측”함
- fig에서는 4, 3, 5가 활성화된다고 예측함
- 이 예측된 weight들만 계산한 뒤 합쳐서 output을 내보냄(fig 2. 참고)
Neuron-aware Inference Engine
- Online 쪽의 디테일을 설명함
- Predictor 어떻게 효율적으로 만들었는지
Adaptive Sparsity Predictors
- 기존 Dejavu에서느 fixed size MLP Predictor를 사용함
- Self attention과 MLP 각각에 대해 Predictor가 별도로 있음
- 이 Predictor의 크기에 따라 성능의 dependency가 크게 생김
- Predictor가 크면 -> 정확도가 올라가는 대신, local에서 못돌릴 VRAM을 사용함
- (⭑)논문에서는 Predictor의 사이즈에 주목함, 특히 2가지 요소에 영향받음을 관측하였음
- LLM 레이어의 sparsity
- 내부의 skewness
- Fig 9.는 x축 (Sparsity)에 따른 성능 95% 정도를 보장하는 Predictor의 파라미터 사이즈(y축)을 나타냄
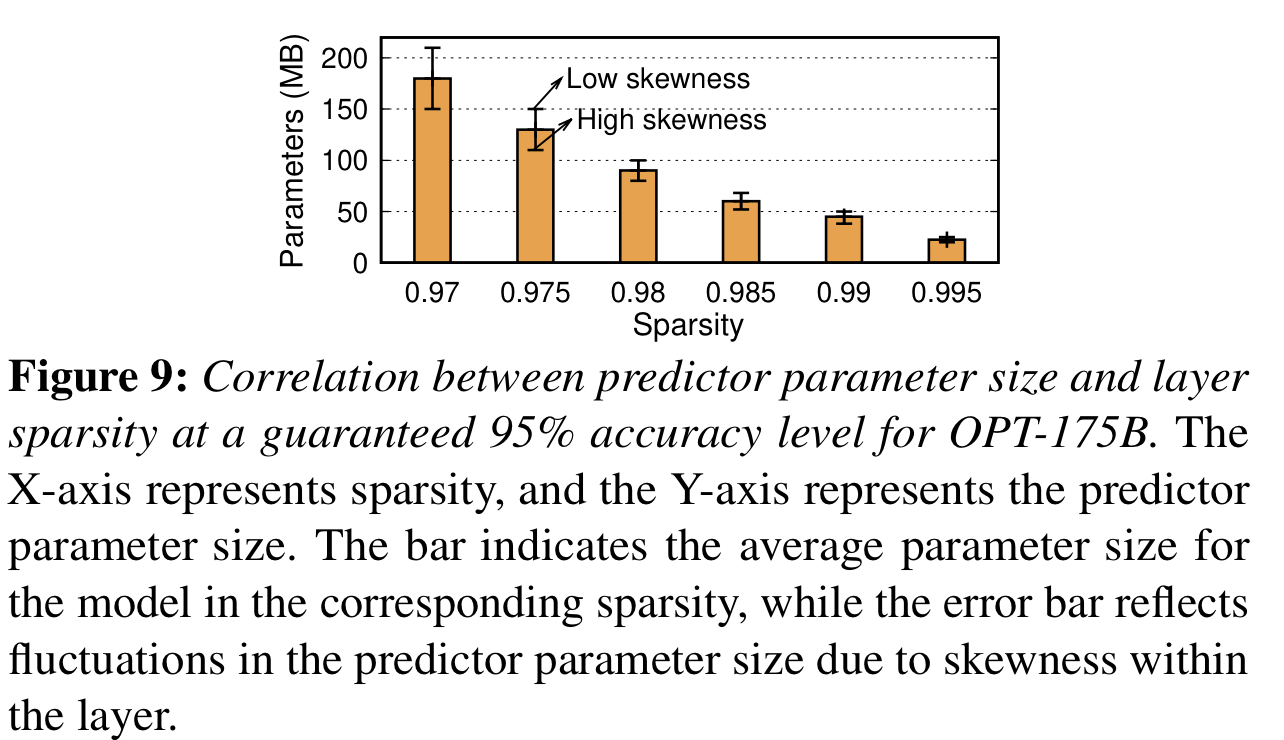
- Sparsity가 크면 Predictor의 파람수가 작아도 충분했음
- Skewness: (아마도) 특정 Neuron에 activation이 몰리는 정도를 의미하는듯,
- Skewness가 크면 Predictor의 파람수가 작아도 충분했음
- 맞추기 쉬워서가 아닐까?
- Skewness가 크면 Predictor의 파람수가 작아도 충분했음
- 위 내용들을 고려해서, non-fixed-size의 predictor를 모든 Transformer layer마다 반복적으로 돌려가며 조절한 뒤 찾음
- (⭑)이를 통해 전체 LLM 모델 파람 수 대비 약 10%로 predictor의 파람 수를 제한함
Neuron Placement and Management
- Neuron table 만들어서 계산 위치의 정확성을 보장하는 것 같음
GPU-CPU Hybrid Execution
- DAG 구조 만들고 글로벌 큐를 두어서 operator를 효율적으로 처리했다는 내용 + 일부 최적화 내용
- 코드 구현을 보는게 좋을듯
Neuron-aware Operator
- 위와 동일한 이유로 생략
Offline Profiling
- Hot/Cold 어떻게 만드는지에 대한 디테일
Neuron Impact Metric
- LLM의 inference 결과에 대한 각 뉴런의 기여도를 측정함
- GPU Neuron allocation을 결정하는 요소
- 프로파일링 도중 activate된 frequency(빈도)로 정의함
Modeling of Neuron Placement
- GPU에서의 모든 Neuron의 impact의 총 합을 최대화하도록 최적화문제를 설정함
- 이를 ILP문제로 정의할 수 있음(아래 이미지)

- 코드
- TBD
- 추가로 Communication Constraint와 Memory Constraint를 고려함
근데 코드보면 아래 내용은 고려 안하는 것 같음..(확인 필요)
- Communication
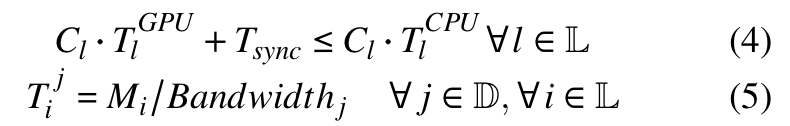
- Memory
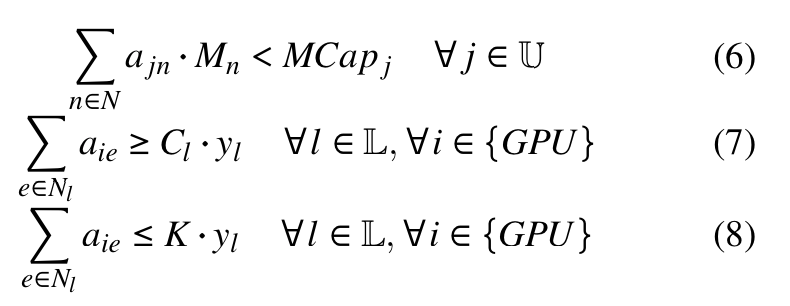
- Communication
ILP Optimization
- 천억개 이상의 파라미터에 대해서 이 문제를 푸는건 어려움
- 비슷한 impact를 가진 Neuron을 64개로 묶어서 배치로 처리해서 문제를 근사함
- 코드보면 activation을 줄세운뒤 비슷한 크기로 64개씩 묶음
- 뒤 최적화부분도 64개로 묶어서 처리
실험
- 언급할만한 내용이..?
- TBD
생각
- 논문의 전개와 직관이 잘 정리되어 좋았음
- 특히 power law에 대한 직관은 pruning 방법의 limitation이 될 수 있어보임
- 무엇보다 실용적임 + 구현체가 잘 되어있다는 점이 마음에 들었음
- llama 레포에서의 discussion에서는 논문의 11x speed up은 cherry-picking이라고 함(Falcon은 llama.cpp에서 잘 처리되지 않는 듯)
- 그렇다 하더라도 3~4x speed up은 큰 benefit
Leave a comment